Napatech SmartNIC Solutions Virtual Switch Acceleration
Solution Description
The following document provides an outline of Napatech SmartNIC solutions for accelerating virtual switching applications, such as Open Virtual Switch (OVS). A range of virtual switch solution options are available, designed to provide performance without compromising flexibility. These include standard solutions that do not require changes to Virtual Network Functions (VNFs) and OVS and enhanced solutions for VNFs that need maximum throughput and zero packet loss, such as virtual probes and appliances for network management and cyber security.
There are two standard solutions available. The first solution is based on partial offload of the virtual switch megaflow cache providing a fast-path for data-plane traffic that can improve performance by up to 80% compared to OVS+DPDK and standard NICs. The second solution extends this concept by directly transferring data to the memory of the VNF using DMA channels and virtio. While similar to SR-IOV in concept and performance, it provides a number of advantages, chief of which are that the solution is based on standard mechanisms, does not require changes to the VNF and provides the ability to migrate VNFs quickly and easily.
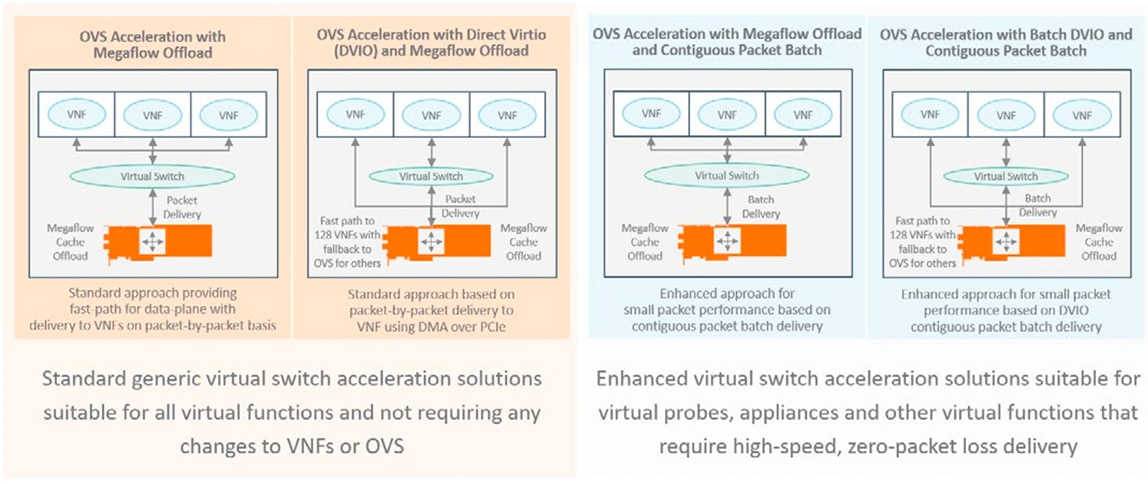
Figure 1: Napatech SmartNIC Solutions for Virtual Switch Acceleration
For VNFs that need maximum throughput and zero packet loss, both of the above solutions can be enhanced using Contiguous Packet Batching. While the standard solutions above transfer data packet-by-packet, with Contiguous Packet Batching, a batch of hundreds of packets are transfered dramatically reducing the amount of processing that needs to be performed and thereby improving throughput.
With all these solutions, the number of CPU cores needed to transfer data can be dramatically reduced allowing more revenue generating VNFs, applications and services to be supported.
THE BENEFIT FOR THE CUSTOMER
At a data center level, saving CPU cores translates into several million dollars in savings. In addition, the ability to handle data at full theoretical throughput ensures that all services are working optimally and that the density of virtual functions per server can be increased. Because SR-IOV is not used and VNFs are not tied to NIC hardware, there are no limitations on where and when virtual functions can be instantiated in the data center allowing more flexibility and agility in service-chain creation and the ability to optimize resource usage at the data center level leading to further operational cost savings.
NAPATECH SMARTNIC SOLUTIONS FOR VIRTUAL SWITCH ACCELERATION
The following provides a brief overview of each virtual switch acceleration solution using OVS as an example.
The virtual switch acceleration solutions are based on a reconfigurable FPGA-based SmartNIC where the NIC Ethernet PHY and MAC are defined in the FPGA allowing the same hardware to support multiple physical port speed rates from 1G to 10G, 25G, 40G, 50G and 100G. Additional features can be added on-the-fly through a remote reconfiguration of the FPGA and this can include combining the virtual switch acceleration solution with other solutions such as virtual machine to virtual machine east- west traffic monitoring or hardware offload of functions, such as encryption and compression.
OVS ACCELERATION WITH MEGAFLOW OFFLOAD
This solution is based on a standard OVS+DPDK distribution with the addition of partial offload of megaflows. It allows the megaflow cache in the SmartNIC hardware to be automatically updated when a change is made to the OVS megaflow cache thereby enabling hardware acceleration of north-south and east-west data-plane traffic being switched through OVS. In addition, the solution provides VLAN/VxLAN/NvGRE/GENEVE encapsulation and decapsulation functionality.
The solution is designed for fast integration with minimal impact and does not require any changes to virtual functions. In addition, it provides an 80% improvement in performance compared to OVS+DPDK on a standard NIC. The megaflow cache offload solution is planned to be upstreamed to the OVS community.
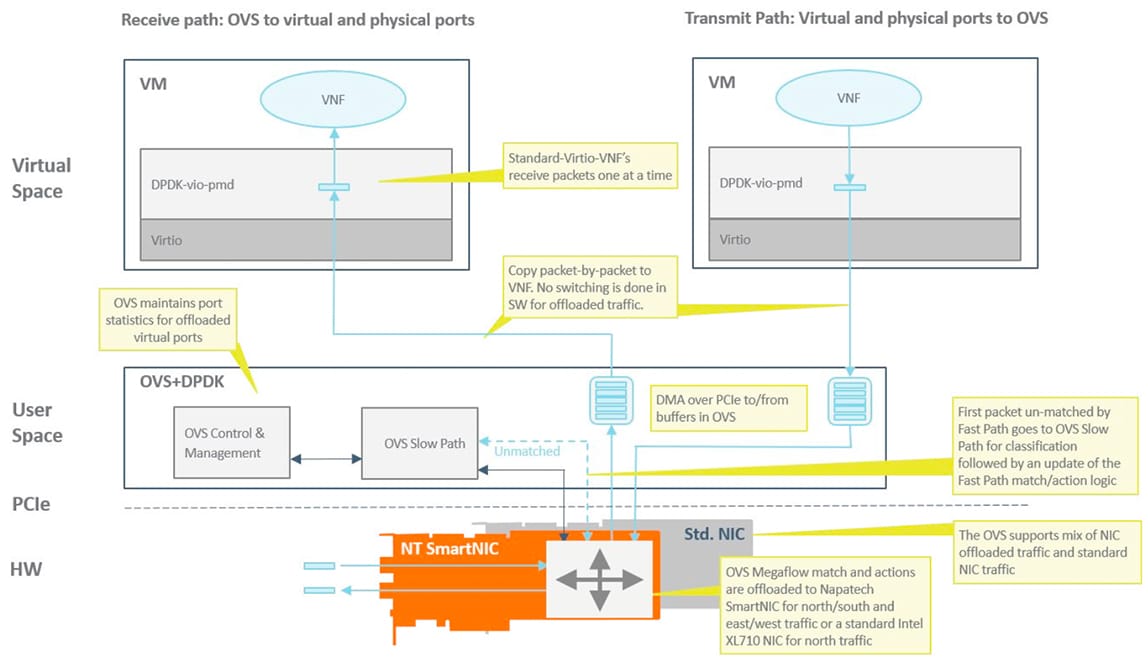
Figure 2: OVS Acceleration with Megaflow Offload
OVS ACCELERATION WITH DIRECT VIRTIO (DVIO) AND MEGAFLOW OFFLOAD
This solution is based on a standard OVS+DPDK distribution and includes all of the functionality and features of the OVS acceleration with Megaflow offload solution above. Instead of transferring data to VNFs through OVS, a Direct Virtio (DVIO) solution is used.
The DVIO solution is based on a Direct Memory Access (DMA) engine on the SmartNIC that is responsible for transferring data over the server PCIe interface from the SmartNIC to the VNF. This means that no OVS resources are used for switching, which dramatically reduces the CPU load. Up to 128 DMA channels are available for DVIO, which means up to 128 VNFs can be serviced with DVIO acceleration. Additional VNFs revert back to switching via OVS in software.
This solution is similar in concept to SR-IOV in that it bypasses the virtual switch in the hypervisor. However, unlike SR-IOV, DVIO does not use the concept of virtual NIC interfaces but relies on the virtio interface, which means that VNFs can be migrated and are not tied to the SmartNIC hardware.
With DVIO, it is possible to delivery 2 ports of 40G traffic to a VNF without consuming any CPU cores with full VNF mobility.
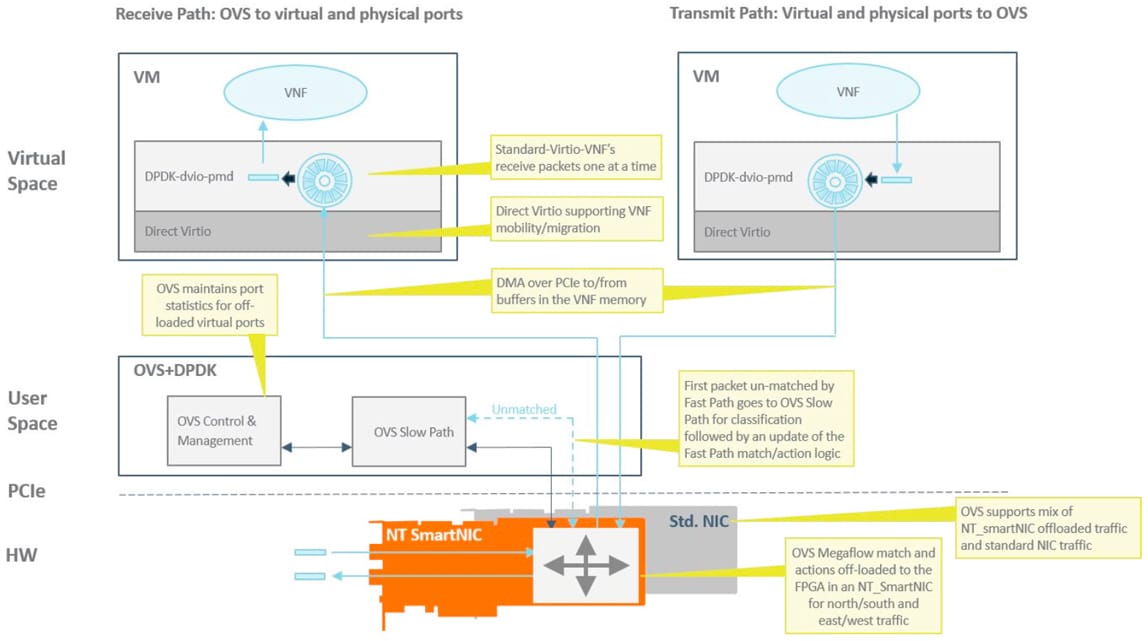
Figure 3: OVS with Direct Virtio (DVIO) and Megaflow Offload
OVS ACCELERATION WITH CONTIGUOUS PACKET BATCHING
Both of the solutions above can be considered standard solutions in that they use standard mechanisms and do not require changes to VNFs in order to provide performance improvements. Nevertheless, there are applications and VNFs that need a higher level of performance than existing standard solutions can provide. This includes virtual probe and appliance applications for network management and cyber security, where maximum theoretical throughput and zero packet loss are required.
To address these more demanding requirements, Napatech can provide enhancements to the OVS Acceleration with Megaflow Offload and OVS Acceleration with DVIO and Megaflow Offload solutions based on Contiguous Packet Batching.
With Contiguous Packet Batching, data is no longer transferred on a packet-by-packet basis, but in batches of packets. Since the megaflow cache is offloaded, it is possible for the SmartNIC to collect packets for specific VNFs and place them in batches in contiguous order. This will ensure that memory caches are used efficiently and pre-fetching mechanisms work effectively reducing the latency associated with memory reads.
If the contiguous packet batch is switched via OVS, it appears as a jumbo frame and will result in a single switch operation rather than hundreds of operations in the packet-by-packet case. This dramatically decreases CPU load.
A contiguous packet batch approach can provide significant performance improvements even if a VNF does not support matching and the packets need to be memory copied and delivered on a packet-by-packet basis. However, the full benefit of contiguous packet batching is experienced when the VNF is “batch-aware” and capable of receiving the batch directly.
With Contiguous Packet Batching, it is possible to delivery 2 ports of 100G traffic to a VNF without consuming any CPU cores with full VNF mobility when using DVIO and using 2 cores when switching through OVS.
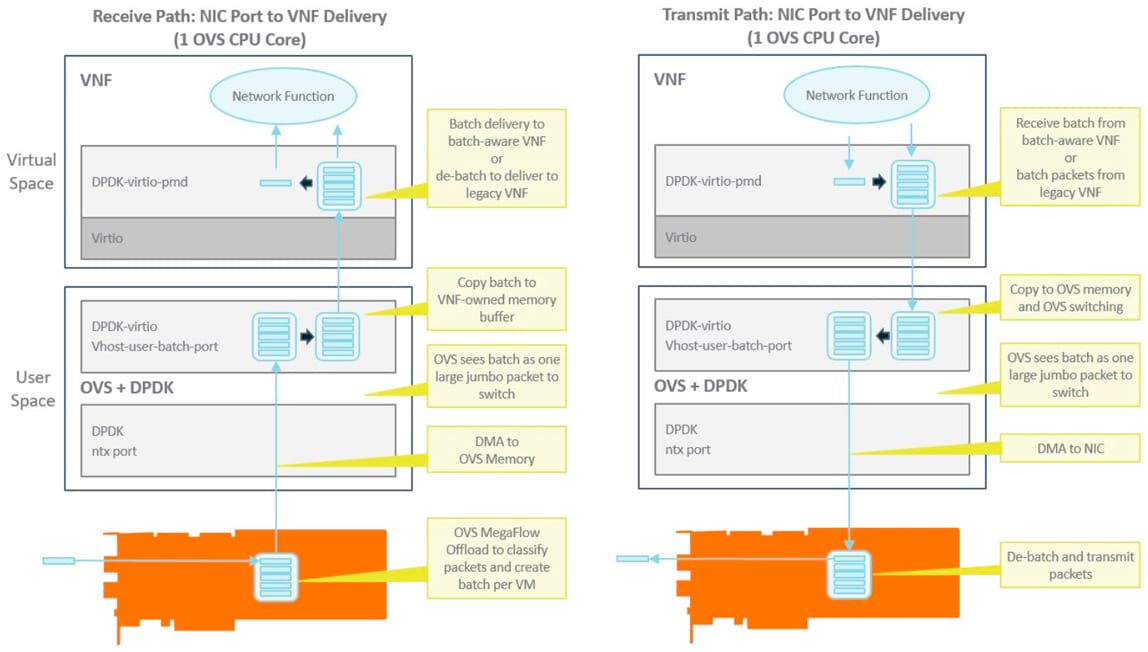
Figure 4: Contiguous Packet Batching
ALTERNATIVE SOLUTION THAT COMBINES PERFORMANCE, FLEXIBILITY AND COST-EFFICIENCY
The Napatech SmartNIC Solutions for Virtual Switch Acceleration provide an alternative to existing data delivery solutions in virtual environments. As the results show, it is no longer necessary to compromise on performance or flexibility, but possible to achieve both. In addition, the solution minimizes the number of CPU cores required for data delivery to the minimum. This reduces CAPEX and OPEX costs of server resources at the data center level by several million dollars while also providing the opportunity to consolidate virtual functions on as few servers as possible, further reducing OPEX costs.
![]()