![]()
Link-Capture™ Software
for Napatech FPGA-based SmartNICs
Link-Capture™ Software is ideal for performing high-speed packet capture with nanosecond timestamping and replay with precise inter-frame gap control, which is critical when replaying captured traffic for troubleshooting or simulation of traffic flows.
The software supports a broad range of applications and use cases – and can immediately improve an organization’s ability to monitor and react to events that occur within its network infrastructure.
• Zero packet loss under all conditions
• Full throughput up to 100 Gbps bi-directional
• Nanosecond timestamping and packet merge
• 140 million flows with stateful match/action
• Flow records with metrics for both directions
• PCAP and DPDK API support
Key Benefits
• Achieve complete network visibility and limit massive costs from cyberattacks or infrastructure issues
• Increase application performance from every server by offloading heavy workloads
• Reduce system costs by using fewer servers to achieve target performance
• Limit OPEX by cutting rack space, power, cooling and management
Multiplied Performance for 3rd Party Applications
Link™ Capture Software has been benchmarked across a wide range of third-party, commercial and open source networking and cybersecurity applications. Common to these is the unconditional requirement for line rate throughput for all packet sizes, with 100% lossless packet forwarding and capture, for a multitude of sessions, users and flows. With Link™ Capture Software, the performance improvements are outstanding, delivering more than triple the performance over servers with standard NIC configurations. This means a third of the required server resources to run the same application.
![]()
Homegrown
Custom-developed apps
With guaranteed zero packet loss and deterministic performance under all conditions, Link-Capture™ Software allows enterprises to develop and deploy their own applications based on low-cost servers.
![]()
Suricata
Intrusion detection and prevention
Link-Capture™ Software is uniquely suited for lossless acceleration of Suricata. Optimized to capture all traffic at full line rate with almost no CPU load on the host server, the solution demonstrates outstanding performance advantages.
![]()
Zeek
Network security monitor
For network security monitors like Zeek, missing the slightest fraction of traffic is unacceptable. Link-Capture™ Software provides 100% lossless packet forwarding and capture, ensuring complete traffic visibility for the application.
![]()
n2disk boost
Network traffic recorder
An unconditional prerequisite for the n2disk™ network traffic recorder application to be successful is that all network packets are captured with zero loss. This is where Link-Capture™ can help.
![]()
Snort
Intrusion detection and prevention
Snort is an ideal example of the type of security app that can achieve better performance with Link-Capture™. The tool is designed to keep up with line rates on commodity hardware, but this requires 100% packet capture.
![]()
TRex
Traffic generator
Optimized for lossless transmit and receive, the Link-Capture™ Software offers substantial performance advantages for TRex: up to 4x traffic transmit performance and 16x reception performance.
![]()
Wireshark
Protocol analyzer
To decode all traffic, it is a fundamental requirement that Wireshark sees everything. If the capture server is overburdened, packets are discarded and information lost forever. Link-Capture™ gives Wireshark a flawless vision.

and more…
Third-party, commercial…
Napatech Link-Capture™ Software transfers data to your application using a non-blocking data delivery mechanism that ensures efficient utilization of the PCIe bus and maximum throughput for all packet sizes.
Watch video: Scaling Security Applications to 100 Gbps with Napatech SmartNICs.
Learn how offloading flows in networking and security architectures frees up CPU resources by using hardware-based action processing of traffic.
Key Features
Link-Capture™ Software for Napatech
Napatech Link-Capture™ Software provides the Napatech SmartNIC family with a common feature set and driver software architecture allowing plug-and-play support for any SmartNIC combination. Key features are listed below.

Stateful Flow Management

Line-rate performance

Packet Buffering

Multi-CPU distribution

Time Stamping

Cache optimization
![]()
Multi-port packet sequence

Tunneling

IP fragments
![]()
Traffic replay

Traffic forwarding

In-line mode

CPU Socket Load Balancer

Correlation key

Deduplication
The intelligent feature set offloads processing and analysis of Ethernet data from application software while ensuring optimal use of the standard server’s resources leading to effective application acceleration. See below for details.
![]()
Stateful Flow Management (NT100A01 and NT200A02 only)
As network speeds continue to rise, the challenge for CPU-bound monitoring and security applications is keeping up with the massive volumes of traffic they need to process. Stateful flow management can help alleviate this challenge by enabling performance improvements at two levels:
– Reducing the load on the application by shunting irrelevant traffic flows
– Accelerating the application using per-flow match/action processing
As offloaded flows are processed entirely by the SmartNIC, stateful flow management enables applications to significantly increase their throughput and save valuable compute cycles. Per-flow match/action in hardware gives control back to the user, providing additional computation to the application by reducing the amount of data needed for processing, as certain flows or protocols no longer need monitoring and can be blocked in hardware.
For every packet, the stateful flow management feature can perform a lookup in the flow table and perform any needed updates, like changing timestamp, incrementing metrics, changing state, and writing the updated flow record back to the flow table. This significantly offloads CPU-bound applications, such as application/network monitoring apps, telecom subscriber analytics apps, or intrusion detection systems (IDS) with a similar requirement for forwarding or dropping packets based on a flow table lookup.
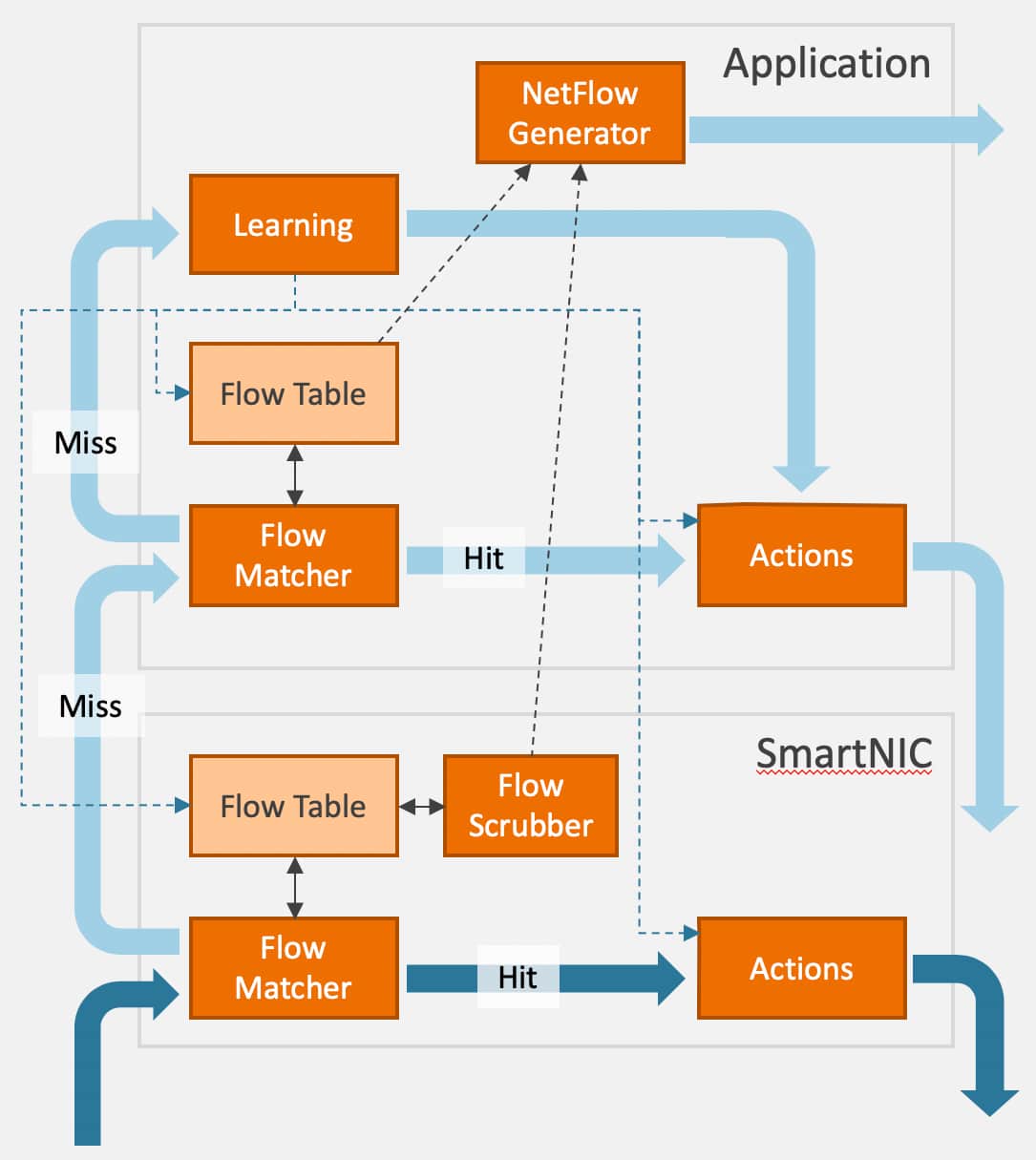
In this diagram, the stateful flow management feature is used to offload an application, in this instance a NetFlow generator. When the first packet arrives, it is not recognized by the flow management and the packet is therefore forwarded to the host application (slow path). The host application saves the needed meta data and metrics from the first packet and offloads the following flows to the hardware by configuring the flow management to shunt similar flows. If more packets arrive before the feature has been configured for flow shunting, these will also be forwarded to the application which will collect the meta data and handle the packet as configured.
Next, the flow is terminated through timeout or TCP flow termination, and a flow termination event is generated by the flow management and sent to the application. This record will contain information about the flow and the meta data collected. The application can then combine the meta data collected by the flow management with the meta data collected by the application, build the NetFlow record and send it off to an external flow collector.
Line-rate performance
Napatech FPGA SmartNICs are highly optimized to capture network traffic at full line-rate, with almost no CPU load on the host server, for all frame sizes. Zero-loss packet capture is critical for applications that need to analyze all the network traffic. If anything needs to be discarded, it is a matter of choice by the application, not a limitation of the SmartNIC.
Standard network interface cards (NICs) are not designed for analysis applications where all traffic on a connection or link needs to be analyzed. NICs are designed for communication where data that is not addressed to the sender or receiver is simply discarded. This means that NICs are not designed to have the capacity to handle the amount of data that is regularly transmitted in bursts on Ethernet connections. In these burst situations, all of the bandwidth of a connection is used, requiring the capacity to analyze all Ethernet frames. Napatech FPGA SmartNICs are designed specifically for this task and provide the maximum theoretical packet capture capacity.
Packet Buffering
Napatech FPGA SmartNICs provide on-board memory for buffering of Ethernet frames. Buffering assures guaranteed delivery of data, even when there is congestion in the delivery of data to the application. There are three potential sources of congestion: the PCI interface, the server platform, and the analysis application.
PCI interfaces provide a fixed bandwidth for transfer of data from the SmartNIC to the application. This limits the amount of data that can be continuously transferred from the network to the application. For example, a 16-lane PCIe Gen3 interface can transfer up to 115 Gbps of data to the application. If the network speed is 2×100 Gbps, a burst of data cannot be transferred over the PCIe Gen3 interface in real time, since the data rate is twice the maximum PCIe bandwidth. In this case, the onboard packet buffering on the Napatech SmartNIC can absorb the burst and ensure that none of the data is lost, allowing the frames to be transferred once the burst has passed.
Servers and applications can be configured in such a way that congestion can occur in the server infrastructure or in the application itself. The CPU cores can be busy processing or retrieving data from remote caches and memory locations, which means that new Ethernet frames cannot be transferred from the SmartNIC.
In addition, the application can be configured with only one or a few processing threads, which can result in the application being overloaded, meaning that new Ethernet frames cannot be transferred. With onboard packet buffering, the Ethernet frames can be delayed until the server or the application is ready to accept them. This ensures that no Ethernet frames are lost and that all the data is made available for analysis when needed.
Load distribution
Multi-CPU distribution
Modern servers provide unprecedented processing power with multi-core CPU implementations. This makes standard servers an ideal platform for appliance development. But, to fully harness the processing power of modern servers, it is important that the analysis application is multi-threaded and that the right Ethernet frames are provided to the right CPU core for processing. Not only that, but the frames must be provided at the right time to ensure that analysis can be performed in real time.
Napatech Multi-CPU distribution is built and optimized from our extensive knowledge of server architecture, as well as real life experience from our customers.
Napatech FPGA SmartNICs ensure that identified flows of related Ethernet frames are distributed in an optimal way to the available CPU cores. This ensures that the processing load is balanced across the available processing resources, and that the right frames are being processed by the right CPU cores.
With flow distribution to multiple CPU cores, the throughput performance of the analysis application can be increased linearly with the number of cores, up to 128. Not only that, but the performance can also be scaled by faster processing cores. This highly flexible mechanism enables many different ways of designing a solution and provides the ability to optimize for cost and/or performance.
Napatech FPGA SmartNICs support different distribution schemes that are fully configurable:
• Distribution per port: all frames captured on a physical port are transferred to the same CPU or a range of CPU cores for processing
• Distribution per traffic type: frames of the same protocol type are transferred to the same CPU or a range of CPU cores for processing
• Distribution by flows: frames with the same hash value are sent to the same CPU or a range of CPU cores for processing
• Combinations of the above
VLAN Tagging
Add VLAN Tags to distribute traffic load outside the server – using the same hashing/filtering functions as when you distribute traffic to the CPU cores on the local server. This enables you to send packets to multiple remote servers/appliances (e.g., IDS, SIEM or for data collection) via a VLAN switch. Inside the remote servers you can then use the local NIC to distribute traffic using Receive Side Scaling (RSS).
• Distribute traffic outside the local server
• Use VLAN switch to scale to multiple servers
• Distribute to multiple remote servers
• Distribute to multiple CPU cores in remote servers
• Distribute based on flow type or traffic type
• Split traffic so that traffic without VLAN tags go the host while traffic with VLAN tags return to the network
Time Stamping
The ability to establish the precise time when frames have been captured or transmitted is critical to many applications.
To achieve this, all Napatech FPGA SmartNICs can provide a high-precision time stamp, sampled with 1 nanosecond resolution, for every frame captured and transmitted.
At 10 Gbps, an Ethernet frame can be received and transmitted every 67 nanoseconds. At 100 Gbps, this time is reduced to 6.7 nanoseconds. This makes nanosecond-precision time-stamping essential for uniquely identifying when a frame is received. This high precision also enables you to sequence and merge frames from multiple ports on multiple FPGA SmartNICs into a single, time-ordered analysis stream.
Test & Measurements applications can utilize Napatech’s nanosecond hardware transmit and receive timestamping for precision network roundtrip delay and jitter measurements. The application can control transmit time stamp per packet and the time stamp is inserted at an offset relative to L3/L4 headers. L3/L4 checksums are generated in hardware, enabling test and measurements across routed networks. The solution is supported for 10G, 25G, 40G and 100G network speeds.
In order to work smoothly in the different operating systems supported, Napatech FPGA SmartNICs support a range of industry standard time stamp formats and offer a choice of resolution to suit different types of applications.
64-bit time stamp formats:
• 2 Windows formats with 10-ns or 100-ns resolution
• Native UNIX format with 10-ns resolution
• 2 PCAP formats with 1-ns or 1000-ns resolution
Cache optimization
Napatech FPGA SmartNICs use a buffering strategy that allocates a number of large memory buffers where as many packets as possible are placed back-to-back in each buffer. Using this implementation, only the first access to a packet in the buffer is affected by the access time to external memory. Thanks to cache pre-fetch, the subsequent packets are already in the level 1 cache before the CPU needs them. As hundreds or even thousands of packets can be placed in a buffer, a very high CPU cache performance can be achieved leading to application acceleration.
Buffer configuration can have a dramatic effect on the performance of analysis applications. Different applications have different requirements when it comes to latency or processing. It is therefore extremely important that the number and size of buffers can be optimized for the given application. Napatech FPGA SmartNICs make this possible.
The flexible server buffer structure supported by Napatech FPGA SmartNICs can be optimized for different application requirements. For example, applications needing short latency can have frames delivered in small chunks, optionally with a fixed maximum latency. Applications without latency requirements can benefit data delivered in large chunks, providing more effective server CPU processing by having the data. Applications that need to correlate information distributed across packets can configure larger server buffers (up to 128 GB).
Up to 128 buffers can be configured and combined with Napatech multi-CPU distribution (see “Multi-CPU distribution”).
![]()
Multi-port packet sequence
Napatech FPGA SmartNICs typically provide multiple ports. Ports are usually paired, with one port receiving upstream packets and another port receiving downstream packets. Since these two flows going in different directions need to be analyzed as one, packets from both ports must be merged into a single analysis stream. Napatech FPGA SmartNICs can sequence and merge packets received on multiple ports in hardware using the precise time stamps of each Ethernet frame. This is highly efficient and offloads a significant and costly task from the analysis application.
There is a growing need for analysis appliances that are able to monitor and analyze multiple points in the network, and even provide a network-wide view of what is happening. Not only does this require multiple FPGA SmartNICs to be installed in a single appliance, but it also requires that the analysis data from all ports on every accelerator be correlated.
With the Napatech Software Suite, it is possible to sequence and merge the analysis data from multiple FPGA SmartNICs into a single analysis stream. The merging is based on the nanosecond precision time stamps of each Ethernet frame, allowing a time-ordered merge of individual data streams.
Tunneling
In mobile networks, all subscriber Internet traffic is carried in GTP (GPRS Tunneling Protocol) or IP-in-IP tunnels between nodes in the mobile core. IP-in-IP tunnels are also used in enterprise networks. Monitoring traffic over interfaces between these nodes is crucial for assuring Quality of Service (QoS).
Napatech FPGA SmartNICs decode these tunnels, providing the ability to correlate and load balance based on flows inside the tunnels. Analysis applications can use this capability to test, secure, and optimize mobile networks and services. To effectively analyze the multiple services associated with each subscriber, it is important to separate them and analyze each one individually. Napatech FPGA SmartNICs have the capability to identify the contents of tunnels, allowing for analysis of each service used by a subscriber. This quickly provides the needed information to the application, and allows for efficient analysis of network and application traffic. The Napatech features for frame classification, flow identification, filtering, coloring, slicing, and intelligent multi-CPU distribution can thus be applied to the contents of the tunnel rather than the tunnel itself, leading to a more balanced processing and a more efficient analysis.
GTP and IP-in-IP tunneling are powerful features for telecom equipment vendors who need to build mobile network monitoring products. With this feature, Napatech can off-load and accelerate data analysis, allowing customers to focus on optimizing the application, and thereby maximizing the processing resources in standard servers.
IP fragments
IP fragmentation occurs when larger Ethernet frames need to be broken into several fragments in order to be transmitted across the network. This can be due to limitations in certain parts of the network, typically when GTP tunneling protocols are used. Fragmented frames are a challenge for analysis applications, as all fragments must be identified and potentially reassembled before analysis can be performed. Napatech FPGA SmartNICs can identify fragments of the same frame and ensure that these are associated and sent to the same CPU core for processing. This significantly reduces the processing burden for analysis applications.
![]()
Traffic replay
For network security purposes, different traffic scenarios need to be recreated and simulated to toughen the infrastructure. The packets also need to be replayed to understand delays and disruptions caused by traffic bursts/peaks to improve Quality of Service (QoS). With Napatech FPGA SmartNICs, it is easy to setup and specify the test scenario to replay the same PCAP files from real network events at 10G, 40G and 100G link speeds.
Traffic forwarding
Get highest precision timestamping for traffic that needs to be redistributed to multiple network devices. Napatech FPGA SmartNICs systems can forward and/or split traffic captured on a single tapping point to a cluster of servers for processing, without using additional equipment. This is achieved by the Napatech FPGA SmartNICs acting as both Smart Taps and packet capture devices and is apt for multi-box solutions with single tapping points. This feature eliminates the need to implement expensive SmartTaps, time stamping switches, packet brokers and other time sync components.
![]()
In-line mode
The Napatech SmartNIC family supports 100 Gbps in-line applications enabling customers to create powerful, yet flexible in-line solutions on standard servers. The more CPU-demanding the application is, and the higher the speeds of links, the higher the value of this solution. Features include:
• Full throughput bidirectional Rx/Tx up to 100G link speed for any packet size
• Multi-core processing support with up to 128 Rx/Tx streams per SmartNIC
• Customizable hash-based load distribution
• Efficient zero copy roundtrip from Rx to Tx
• Single bit flip selection to discard or forward each individual packet
• Typical 50 us roundtrip latency from Rx to Tx fiber
CPU Socket Load Balancer
Further enhance your CPU utilization with the CPU Socket Load Balancer capability offered by Napatech NT200A02 and NT100A01 FPGA SmartNICs. Improve CPU performance by up to 30% per server for 4 × 1 Gbps, 4 × 10 Gbps, 2 × 40 Gbps, 8 × 10 Gbps analysis with Napatech FPGA SmartNICs that can efficiently distribute traffic to 2 CPU sockets, making the packets available to multiple analysis threads on both CPU sockets, simultaneously. This frees up CPU resources needed for copying data between the two sockets and eliminates the need for expensive QPI bus transfers.
Correlation key
The Napatech correlation key makes it possible to identify and trace the packet propagation through the entire network. The feature adds a unique ‘fingerprint’ to each packet and performs intelligent comparison, taking into consideration potential changes in the header information and checksums.
The correlation key is extremely valuable for applications that need insight into packet latency, timing or route for a variety of purposes, e.g. to analyze and remedy Quality of Experience (QoE) issues caused by peaks or bursts. With this feature, network service providers can perform powerful and cost-effective measurements of QoE characteristics in real time, at all link speeds up to 100G. It enables configuration of up to 16 different conditions depending on traffic category and can be based on packet type or IP address as needed by the application.
The correlation key is also extremely useful for deduplication, e.g. to offload applications by efficiently identifying and discarding duplicate packets.
Deduplication
Whether you are in the business of application performance monitoring, network monitoring, telecom subscriber analytics or network recording, incorrect switch span port configuration is common, which can result in up to 50% duplicate packets. Duplicates can cause a lot of issues. The obvious issue is that double the amount of data requires double the amount of processing power, memory, power, etc. However, the main issue is false positives: errors that are not really errors or threats that are not really threats. Debugging these issues takes a lot of time.
With deduplication built in via a SmartNIC in the appliance, it is possible to detect up to 99.99% of duplicate packets produced by SPAN ports. By filtering out irrelevant packets and discarding redundant data, you benefit by offloading the application as well as saving valuable disk space. Similar functionality is available on packet brokers, but for a sizeable extra license fee. On Napatech SmartNICs, this is just one of several powerful features delivered at no extra charge. Napatech SmartNICs provide the following deduplication features:
• Deduplication in hardware up to 2x100G
• Deduplication key is calculated as a hash over configurable sections of the frame
• Dynamic header information (e.g. TTL) can be masked out from the key calculation
• Enable/disable deduplication per network port or per network port group
• Configurable action per port group: Discard or pass duplicates
• Duplicate counters per port group
• Configurable deduplication window from 10 microseconds to 2 seconds
L2 and L3/L4 (IP/TCP/UDP) Tx Checksums Generation
Generation of checksums is a burden to the application and for high traffic loads checksum generation can be a bottleneck. Napatech Link-Capture™ software supports an advanced scheme for L2 and L3/L4 (IP/TCP/UDP) Tx checksums generation at port speeds up to 2x100G. For each transmitted packet the application can control individually for L2, L3 and L4 how checksums are generated:
• Generate correct checksum
• Generate incorrect checksum
• Leave checksum unchanged
These flexible configuration options can be utilized to implement applications such as:
• Network test with error simulation
• Network capture and exact replay of traffic even with invalid packets
• Network capture and replay with modified IP addresses
• Traffic generation up to 100G link speed with HW offload
L2 and L3/L4 (IP/TCP/UDP) Rx Checksums Verification
Verification of checksums is a burden to the application and for high traffic loads checksum verification can be a bottleneck. Napatech Link-Capture™ software supports L2 and L3/L4 (IP/TCP/UDP) Rx checksum verification at port speeds up to 2x100G. Information about valid/invalid checksums is provided to the application via the API and meta data in packet descriptor. The application can configure filters dynamically to drop or forward packets with valid/invalid checksums to specific host queues.

Packet Slicing
Truncate packets and only preserve the protocol headers required for network analysis. Typical benefits include conserving disk space, reducing trace file size or to remove specific parts of the packets for legal reasons.
• Send packets to the host, return them to the network or do both
• Dynamic offset or fixed offset from start or end of packet

Header Stripping
Remove specified protocol layers which the application does not support. This way, for example, you can remove headers for GTP/MPLS, before sending the packet to the host application and/or retransmitting the packet to the network. When enabled, the headers are removed and the packets are sent to the host (or network), which greatly accelerates applications. You can also use Header Stripping to remove VLAN tags.
• Remove tagging and tunneling protocols
• Generic header stripping can remove anything between identified dynamic offsets

Packet Masking
Some customers may be subjected to strict regulations concerning data confidentiality. Regulations within healthcare and finance, for example, may require that sensitive data be protected, and non-compliance may incur severe penalties. By masking a specific part of the packet before sending it to the application, you can protect sensitive data (e.g., social security number, PIN codes and passwords).
• Supports applications in the local server or in a server connected downlink
• Anonymize sensitive data during analysis
Compatible Napatech FPGA-based SmartNICs
The Link-Capture™ Software is available for our family of FPGA-based SmartNICs.

NT400D11 PCIe4 SmartNIC
2x100G
The Napatech NT400D11 PCIe4 SmartNIC is based on Intel® Agilex™ AGF 014 FPGA architecture and enables 2x100G applications. The QSFP28 form factor offers flexibility to create high-performance solutions in 1U server platforms for existing 100G network infrastructures. Also available in NEBS variants.
NT200A02 SmartNIC
2×1/10G, 8x10G, 2×10/25G, 4×10/25G, 2x40G, 2x100G
The NT200A02 SmartNIC is based on Xilinx’s powerful UltraScale+ VU5P FPGA architecture and enables 8x10G, 2×10/25G, 2x40G or 2x100G applications. The QSFP28 form factor offers flexibility to create high-performance solutions in 1U server platforms for existing 40G network infrastructures, with the freedom to repurpose the solution for 100G installations when necessary. Also available in NEBS variants.

NT100A01 SmartNIC
4×1/10G, 4×10/25G
The NT100A01 SmartNIC is based on Xilinx’s powerful UltraScale+ VU5P FPGA architecture and enables 4×1/10G, 4×10/25G applications. The QSFP28 form factor offers flexibility to create high-performance solutions in 1U server platforms for existing 40G network infrastructures, with the freedom to repurpose the solution for 100G installations when necessary. Also available in NEBS variants.

NT50B01 SmartNIC
2×1/10G, 2×10/25G
The NT50B01 SmartNIC is based on Xilinx’s powerful UltraScale+ VU5P FPGA architecture and enables 2×1/10G, 2×10/25G applications. The QSFP28 form factor offers flexibility to create high-performance solutions in 1U server platforms for existing 40G network infrastructures, with the freedom to repurpose the solution for 100G installations when necessary. Also available in NEBS variants.

NT40A11 SmartNIC
4x1G, 4×1/10G
The NT40A11 SmartNIC provides full packet capture of network data at 40 Gbps with zero packet loss. Nanosecond precision time-stamping and merge of packets from multiple ports ensures correct timing and sequencing of packets. The NT40A11 SmartNIC can also be used for 100% packet replay with nanosecond precision of all networking traffic for analytics, testing and simulation. Also available in a NEBS level 3 compliant variant.
Tech specs
| FEATURES | Link-Capture™ Software for Napatech FPGA SmartNICs |
| Rx Packet Processing | • Line rate Rx up to 100 Gbps for packet size 64 – 10,000 bytes • Zero packet loss • Multi-port packet merge, sequenced in time stamp order |
| L2, L3 and L4 protocol classification | • L2: Ether II, IEEE 802.3 LLC, IEEE 802.3/802.2 SNAP • L2: PPPoE Discovery, PPPoE Session, Raw Novell • L2: ISL, 3x VLAN, 7x MPLS • L3: IPv4, IPv6 • L4: TCP, UDP, ICMP, SCTP • L2 and L3/L4 (IP/TCP/UDP) Tx checksum generation • L2 and L3/L4 (IP/TCP/UDP) Rx checksum verification |
| Tunneling support | • GTP, IP-in-IP, GRE, NVGRE, VxLAN, Pseudowire, Fabric Path |
| General purpose filters | • Pattern match, network port, protocol, length check, error conditions |
| Flow filtering | • Configurable flow definitions based on 2-, 3-, 4-, 5- or 6-tuple • Up to 36,000 IPv4 or up to 7,500 IPv6 2-tuple flows • Flow match/actions: forward to specific host Rx queue, drop, fast forward to network port, select packet descriptor type, slice |
| Stateful flow management (NT100A01 and NT200A02) | • Configurable flow definitions based on 2-, 3-, 4-, 5- or 6-tuple • Up to 140 million bidirectional IPv4 or IPv6 flows • Learning rate: 3 million flows/sec • Flow match/actions: forward to specific host Rx queue, drop, fast forward to network port, update metrics in flow record • Flow termination: TCP protocol, timeout, application- requested • Flow records: Rx packet/byte counters and TCP flags, delivered to application at flow termination |
| Hash keys | • Custom 2 × 128 bits and 2 × 32 bits with separate bit masks • Symmetric hash keys • Protocol field from inner or outer headers |
| Load distribution | • Hash key, filter-based or per flow • To local CPU cores via host buffers/queues • Remotely via VLAN tagging over egress port (NT200A02 and NT100A01) • CPU Socket Load Balancing (NT200A02, NT100A01) |
| Packet descriptors and metadata | • PCAP and Napatech descriptor formats • Time stamp, network port ID, header offsets • Hash key, color/tag • 64-bit pointer for flow lookup • 64-bit correlation key with maskable fields (packet fingerprint) • Protocol and error information |
| IP fragment handling | • First level IP fragmentation • Filter actions on inner header fields applied to all fragments |
| Deduplication | • Configurable action per port group: discard or pass duplicates • Duplicate counters per port group |
| Slicing | • Dynamic offset or fixed offset from start or end of packet |
| Header stripping (NT200A02 and NT100A01) | • Removal of protocol layers between outer L2 and inner L3 headers |
| Packet masking (NT200A02 and NT100A01) | • Zeroing of 1 – 64 bytes at dynamic or fixed offset |
| Tx Packet Processing | • Line rate Tx up to 100 Gbps for packet size 64 – 10,000 bytes • Replay as captured with nanoseconds precision • Per-port traffic shaping • Port-to-any-port forwarding |
| Rx buffer capacity | • NT200A02: 12GB • NT100A01: 8GB • NT50B01: 10GB • NT40A11: 4GB |
| Host Buffers and Queues | • Rx queues: 128, Tx queues: 128 • Rx buffer size: 16 MB – 1 TB, Tx buffer size: 4 MB |
| Advanced Statistics | • Extended RMON1 per port • Packets and bytes per filter/color and per stream/queue |
| Time Stamping and Synchronization | • OS time • PPS and IEEE 1588-2008 PTP V2 (*) • NT-TS synchronization between Napatech SmartNICs (*) • Time stamp formats: Unix 10 ns, Unix 1 ns, PCAP 1 us, PCAP 1 ns • Tx time stamp inject • Rx time stamp with 1 ns resolution |
| Monitoring sensors | • PCB temperature level with alarm • FPGA temperature level with alarm and automatic shutdown • Temperature of critical components • Individual optical port temperature or light level with alarm • Voltage or current overrange with alarm • Cooling fan speed with alarm |
| Supported OS | • Linux kernel 3.0 – 3.19, 4.0 – 4.18, 5.0 – 5.11 (64-bit) • Windows Server 2016 and 2019 (64-bit) |
| Supported APIs | • libpcap v. 1.7.3, 1.8.1, 1.9.0 and WinPcap v. 4.1.3 • DPDK v. 20.11 • NTAPI (Napatech API) |
| Supported Hardware and Transceivers | NT200A02: • 1000BASE-T, SX, LX, ZX • 10GBASE-SR, CR, LR, ER and breakout to 4x10GBASE-SR, CR, LR • 25GBASE-SR, LR, LR-BiDi and breakout to 4x25GBASE-SR, LR • 40GBASE-SR4, SR-BiDi, LR4 • 100GBASE-SR4, SR-BiDi, LR4NT100A01: • 1000BASE-T, SX, LX, ZX • 10GBASE-SR, CR, LR, ER • 25GBASE-SR, LR, LR-BiDiNT50B01: • 10GBASE-SR, CR, LR, ER • 25GBASE-SR, LR, LR-BiDi NT40A11: |
| (*) Not supported by the NT40A11 |
Resources and downloads
![]()
Product Brief and Feature Overview