As Communications Service Providers (CSPs) worldwide scale up the deployments of their 5G networks, they face strong pressure to optimize their Return on Investment (RoI), given the massive expenses they already incurred to acquire spectrum as well as the ongoing costs of infrastructure rollouts.
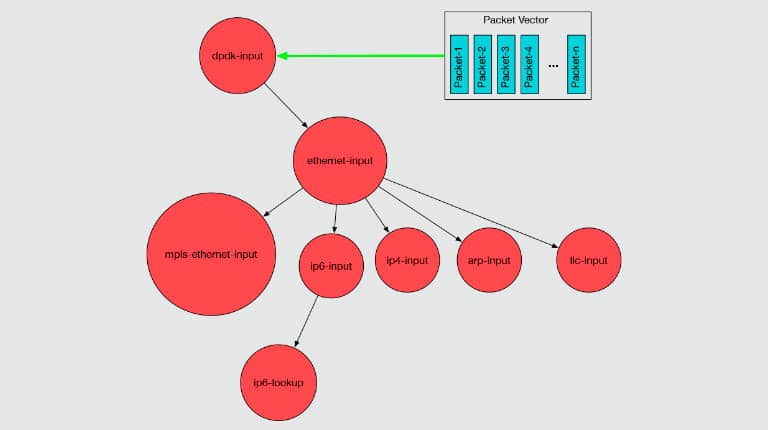
VPP – What performance to expect from a 2x100GbE NIC
VPP – How does it perform with Napatech?
VPP – Vector Packet Processing, has been on my radar for a while. Although I have been following the work for some time now, I’ve never worked hands-on with it. As part of my series of experiments to see how well the Napatech DPDK adapts into existing open-source DPDK-based programs, I decided to give VPP a go.
The scope of the VPP exploration was to:
- Get VPP up running using the Napatech DPDK library.
- Check the out-of-the-box performance of L3 switching on Napatech to get a base-line.
- Offload the L2 and L3 graph-nodes to see how much acceleration could be achieved
- See how it runs on a 100GbE NIC.
The task didn’t go as expected. The out-of-the-box performance of the Napatech NIC was not as expected. Instead of spending my time on accelerating L2 and L3, I spent it optimizing the Napatech driver. The result was that I ended up with a very nice out-of-the-box experience along with some very good performance numbers, also for 100GbE.
VPP – Getting it to run with Napatech
My aim was to get VPP to use a Napatech DPDK dynamic lib installed in /opt/dpdk. In order to do this, I had to patch the Makefile system because it expects the dpdk libraries to be detected in the default install path and it initializes LD_LIBRARY_PATH internally without adding existing LD_LIBRARY_PATH paths.
diff --git a/build-root/Makefile b/build-root/Makefile
index 81f7b901..4310b8ed 100644
--- a/build-root/Makefile
+++ b/build-root/Makefile
@@ -318,7 +318,7 @@ BUILD_ENV = \
export PATH=$(TOOL_INSTALL_DIR)/ccache-bin:$(TOOL_INSTALL_DIR)/bin:$${PATH} ; \
export PATH="`echo $${PATH} | sed -e s/[.]://`" ; \
$(if $(not_native),export CONFIG_SITE=$(MU_BUILD_ROOT_DIR)/config.site ;,) \
- export LD_LIBRARY_PATH=$(TOOL_INSTALL_DIR)/lib64:$(TOOL_INSTALL_DIR)/lib ; \
+ export LD_LIBRARY_PATH=$(LD_LIBRARY_PATH);$(TOOL_INSTALL_DIR)/lib64:$(TOOL_INSTALL_DIR)/lib ; \
set -eu$(BUILD_DEBUG) ; \
set -o pipefail
As with TRex, VPP also needs to be made aware of the Napatech NIC, so I had to additionally include some lines of code to the VPP code base, although it was not as extensive as for TRex (see https://www.napatech.com/100gbe-traffic-generation-using-trex/)
diff --git a/build-root/Makefile b/build-root/Makefile
index 81f7b901..4310b8ed 100644
--- a/build-root/Makefile
+++ b/build-root/Makefile
@@ -318,7 +318,7 @@ BUILD_ENV = \
export PATH=$(TOOL_INSTALL_DIR)/ccache-bin:$(TOOL_INSTALL_DIR)/bin:$${PATH} ; \
export PATH="`echo $${PATH} | sed -e s/[.]://`" ; \
$(if $(not_native),export CONFIG_SITE=$(MU_BUILD_ROOT_DIR)/config.site ;,) \
- export LD_LIBRARY_PATH=$(TOOL_INSTALL_DIR)/lib64:$(TOOL_INSTALL_DIR)/lib ; \
+ export LD_LIBRARY_PATH=$(LD_LIBRARY_PATH);$(TOOL_INSTALL_DIR)/lib64:$(TOOL_INSTALL_DIR)/lib ; \
set -eu$(BUILD_DEBUG) ; \
set -o pipefail
diff --git a/src/plugins/dpdk/device/dpdk.h b/src/plugins/dpdk/device/dpdk.h
index 9762c713..39a1b12a 100644
--- a/src/plugins/dpdk/device/dpdk.h
+++ b/src/plugins/dpdk/device/dpdk.h
@@ -76,7 +76,8 @@ extern vlib_node_registration_t dpdk_input_node;
_ ("net_mlx5", MLX5) \
_ ("net_dpaa2", DPAA2) \
_ ("net_virtio_user", VIRTIO_USER) \
- _ ("net_vhost", VHOST_ETHER)
+ _ ("net_vhost", VHOST_ETHER) \
+ _ ("net_ntacc", NTACC)
typedef enum
{
diff --git a/src/plugins/dpdk/device/format.c b/src/plugins/dpdk/device/format.c
index 697bdbe5..9c4e055d 100644
--- a/src/plugins/dpdk/device/format.c
+++ b/src/plugins/dpdk/device/format.c
@@ -326,6 +326,10 @@ format_dpdk_device_type (u8 * s, va_list * args)
dev_type = "VhostEthernet";
break;
+ case VNET_DPDK_PMD_NTACC:
+ dev_type ="Napatech NTACC";
+ break;
+
default:
case VNET_DPDK_PMD_UNKNOWN:
dev_type = "### UNKNOWN ###";
diff --git a/src/plugins/dpdk/device/init.c b/src/plugins/dpdk/device/init.c
index acf712ff..b046e00e 100755
--- a/src/plugins/dpdk/device/init.c
+++ b/src/plugins/dpdk/device/init.c
@@ -355,7 +355,8 @@ dpdk_lib_init (dpdk_main_t * dm)
DPDK_DEVICE_FLAG_INTEL_PHDR_CKSUM;
break;
- case VNET_DPDK_PMD_CXGBE:
+ case VNET_DPDK_PMD_NTACC:
+ case VNET_DPDK_PMD_CXGBE:
case VNET_DPDK_PMD_MLX4:
case VNET_DPDK_PMD_MLX5:
xd->port_type = port_type_from_speed_capa (&dev_info);
@@ -1331,6 +1332,9 @@ dpdk_update_link_state (dpdk_device_t * xd, f64 now)
case ETH_SPEED_NUM_40G:
hw_flags |= VNET_HW_INTERFACE_FLAG_SPEED_40G;
break;
+ case ETH_SPEED_NUM_100G:
+ hw_flags |= VNET_HW_INTERFACE_FLAG_SPEED_100G;
+ break;
case 0:
break;
default:
With the changes above in place I was able to build VPP using the following:
make vpp_uses_external_dpdk=yes vpp_dpdk_inc_dir=/opt/dpdk/include vpp_dpdk_lib_dir=/opt/dpdk/lib vpp_dpdk_shared_lib=yes bootstrap
make vpp_uses_external_dpdk=yes vpp_dpdk_inc_dir=/opt/dpdk/include vpp_dpdk_lib_dir=/opt/dpdk/lib vpp_dpdk_shared_lib=yes build-release -j48
VPP was downloaded, extracted and built in /opt/vpp.
VPP – Out-of-the-box-performance, ouch Napatech!
Normally when I run DPDK applications on Napatech I get very good performance numbers, at least equal to or better than standard Intel based NICs. This time with VPP, the Napatech NIC performed worse than a standard NIC.
The measurements were made using 1 core per interface doing L3 switching from one port to the other.
Startup.conf
unix {
interactive
nodaemon
log /tmp/vpp.log
cli-listen /run/vpp/cli.sock
}
cpu {
main-core 0
corelist-workers 2,4,6,8,10,12,14,16
}
dpdk {
socket-mem 2048,2048
# Napatech NT40E3-4
dev 0000:04:00.0
# Intel X710 port 0
dev 0000:05:00.0
# Intel X710 port 1
dev 0000:05:00.1
num-mbufs 61440<
}
vpp_run.sh script
#!/bin/bash
DPDK_DIR="/opt/dpdk/lib"
T=/opt/vpp/build-root/install-vpp-native/vpp
/bin/rm -f /dev/shm/db /dev/shm/global_vm /dev/shm/vpe-api || return
LD_LIBRARY_PATH=$DPDK_DIR $T/bin/vpp -c /opt/vpp/startup.conf
VPP setup
vpp# show int
Name Idx State Counter Count
TenGigabitEthernet4/0/0/0 1 down
TenGigabitEthernet4/0/0/1 2 down
TenGigabitEthernet4/0/0/2 3 down
TenGigabitEthernet4/0/0/3 4 down
TenGigabitEthernet5/0/0 5 down
TenGigabitEthernet6/0/0 6 down
local0 0 down
vpp# set int state TenGigabitEthernet4/0/0/0 up
vpp# set int state TenGigabitEthernet4/0/0/1 up
vpp# set int state TenGigabitEthernet5/0/0 up
vpp# set int state TenGigabitEthernet5/0/1 up
vpp# set interface ip address TenGigabitEthernet4/0/0/0 1.1.1.1/24
vpp# set interface ip address TenGigabitEthernet4/0/0/1 1.1.2.1/24
vpp# set interface ip address TenGigabitEthernet5/0/0 1.1.3.1/24
vpp# set interface ip address TenGigabitEthernet5/0/1 1.1.4.1/2

The first out-of-the-box measurement showed 10.6 Gbps L3 switching using the Napatech NIC, whereas Intel was 15.8 Gbps using the X710 (the X520 achieved 15.2 Gbps).
New RX/TX DPDK PMD
Now instead of doing what I initially planned, which was offloading L2 and L3 to HW, I spent some time trying to optimize the Napatech PMD to get a baseline that was on par or better than the Intel NICs. I rewrote the Napatech driver to expose the HW rings to DPDK and rewrote the PMD to utilize the RX/TX rings directly instead of going through the NTAPI abstraction layer. The RX part was not accelerated that much by this, but the TX part gave quite a boost, but still below a standard NIC.
Cache, cache, cache
Still not having achieved my goal, I started profiling VPP and comparing Intel vs Napatech NIC usage especially looking for cache-misses, because usually that is where you get the first couple of low-hanging fruits when doing performance optimizations. X710 has the following “perf” numbers after a ~10sec L3 switching run:
# perf stat -e task-clock,cycles,instructions,cache-references,cache-misses,LLC-loads,LLC-load-misses -p `pgrep vpp_main` #-t `ps -eL | grep vpp_wk_0 | cut -d" " -f 2`
^C
Performance counter stats for process id '162424':
90075.433156 task-clock (msec) # 8.009 CPUs utilized
279,015,176,706 cycles # 3.098 GHz
738,354,872,777 instructions # 2.65 insn per cycle
2,458,863,457 cache-references # 27.298 M/sec
305,349 cache-misses # 0.012 % of all cache refs
2,117,676,112 LLC-loads # 23.510 M/sec
120,289 LLC-load-misses # 0.01% of all LL-cache hits
11.246247956 seconds time elapsed
The Napatech NIC has the following numbers:
# perf stat -e task-clock,cycles,instructions,cache-references,cache-misses,LLC-loads,LLC-load-misses -p `pgrep vpp_main` #-t `ps -eL | grep vpp_wk_0 | cut -d" " -f 2`
^C
Performance counter stats for process id '18971':
81574.853471 task-clock (msec) # 8.003 CPUs utilized
251,498,095,181 cycles # 3.083 GHz (66.67%)
742,381,995,403 instructions # 2.95 insn per cycle (83.33%)
602,825,052 cache-references # 7.390 M/sec (83.33%)
130,588,621 cache-misses # 21.663 % of all cache refs (83.33%)
460,007,648 LLC-loads # 5.639 M/sec (83.34%)
73,882,302 LLC-load-misses # 16.06% of all LL-cache hits (83.34%)
10.193400470 seconds time elapsed
On comparing the two “perf” runs, it was clear that the Napatech NIC has a cache access problem that needed addressing. After some deeper investigations I found that the RX/TX rings were too big and lowering them helped quite a bit, so now I got the following perf results:
# perf stat -e task-clock,cycles,instructions,cache-references,cache-misses,LLC-loads,LLC-load-misses -p `pgrep vpp_main` #-t `ps -eL | grep vpp_wk_0 | cut -d" " -f 2`
^C
Performance counter stats for process id '23210':
87355.966499 task-clock (msec) # 8.003 CPUs utilized
269,451,121,592 cycles # 3.085 GHz (66.67%)
835,061,638,384 instructions # 3.10 insn per cycle (83.34%)
297,931,758 cache-references # 3.411 M/sec (83.34%)
298,121 cache-misses # 0.100 % of all cache refs (83.33%)
181,800,174 LLC-loads # 2.081 M/sec (83.34%)
105,273 LLC-load-misses # 0.06% of all LL-cache hits (83.33%)
10.915675642 seconds time elapsed
The performance with the new RX/TX ring sizes was L3 switching of 16.6Gbps, so now the Napatech base-line was higher than a standard NIC. Now, I could have done the L2-L3 offloading at this point but, I was kind of disappointed by the throughput, so I also spent some time investigating the “L2 xconnect” and “L2 bridge” performance.
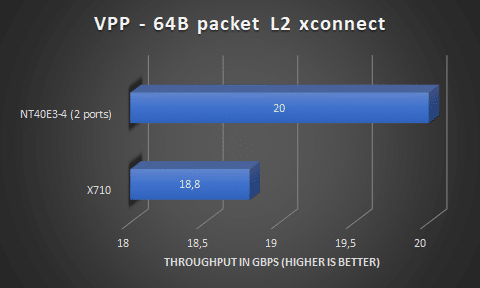
L2 xconnect
The L2 xconnect must be the highest performing mode in VPP because it is basically looping traffic from one port the other. I expected the Napatech NIC to perform @20Gbps here, which it also did. VPP setup:
vpp# set int state TenGigabitEthernet4/0/0/0 up
vpp# set int state TenGigabitEthernet4/0/0/1 up
vpp# set int state TenGigabitEthernet5/0/0 up
vpp# set int state TenGigabitEthernet5/0/1 up
vpp# set int l2 xconnect TenGigabitEthernet4/0/0/0 TenGigabitEthernet4/0/0/1
vpp# set int l2 xconnect TenGigabitEthernet4/0/0/1 TenGigabitEthernet4/0/0/0
vpp# set int l2 xconnect TenGigabitEthernet5/0/0 TenGigabitEthernet5/0/1
vpp# set int l2 xconnect TenGigabitEthernet5/0/1 TenGigabitEthernet5/0/0
L2 bridging
After L2 xconnect, a L2 bridge must be the next highest performing operation.
vpp# set int state TenGigabitEthernet4/0/0/0 up
vpp# set int state TenGigabitEthernet4/0/0/1 up
vpp# set int state TenGigabitEthernet5/0/0 up
vpp# set int state TenGigabitEthernet5/0/1 up
vpp# set interface l2 bridge TenGigabitEthernet4/0/0/0 200
vpp# set interface l2 bridge TenGigabitEthernet4/0/0/1 200
vpp# set interface l2 bridge TenGigabitEthernet5/0/0 200
vpp# set interface l2 bridge TenGigabitEthernet5/0/1 200
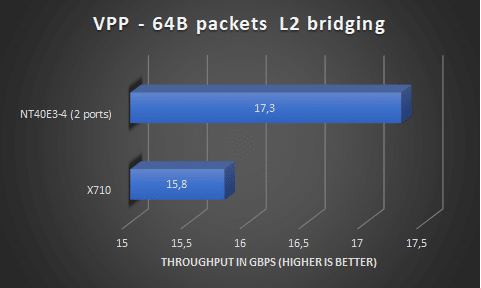
With a L2 bridge setup I was not able to run @20Gbps using 1 core per interface, I could so 17.3Gbps.
100GbE results
All the time was spent doing performance debugging and throughput measurements, so I dropped the idea of doing L2-L3 offloading and turned my attention to 100GbE instead. The only non-Napatech 100GbE NIC I have is the Mellanox ConnectX-5 ( CX516A) so I wanted to compare it against the Napatech NT200A02 NIC The system I have is a Dell R730, but it only has one x16 PCIe connector and that is connect to Socket1 (NUMA1):
# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E5-2690 v3 @ 2.60GHz
Stepping: 2
CPU MHz: 1199.960
CPU max MHz: 3100.0000
CPU min MHz: 1200.0000
BogoMIPS: 5199.46
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 30720K
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43,45,47
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm epb tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm xsaveopt cqm_llc cqm_occup_llc dtherm ida arat pln pts
Mellanox or Napatech
Since I only have 12 cores (24 with hyper-threading) per NUMA node, I wanted to choose the NIC what with 6 cores per interface achieved the highest performance. I created a setup where I generated 50Gbps on each port and measured the L2 xconnect throughput at different packet sizes, to find the NIC to use for my further tests.
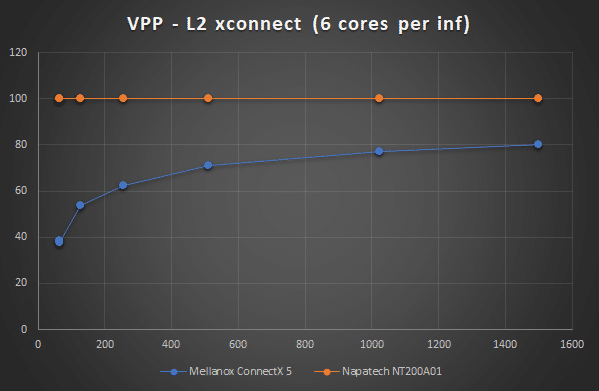
I was disappointed by the Mellanox numbers, I had expected them to be higher especially when I read some of their own DPDK benchmarks (https://fast.dpdk.org/doc/perf/DPDK_17_02_Mellanox_NIC_performance_report.pdf). Based on the performance numbers I chose to continue my tests using the NT200A01 NIC. The purpose of these tests was to see how many cores were needed to handle 100Gbps (2x50Gbps) when doing:
- L2 xconnect
- L2 bridging
- L3 switching
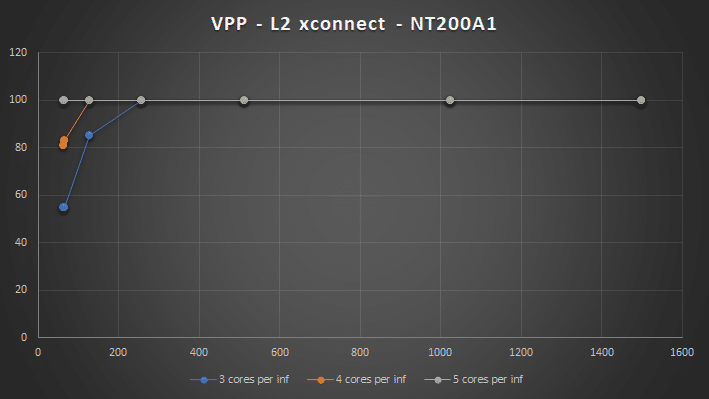
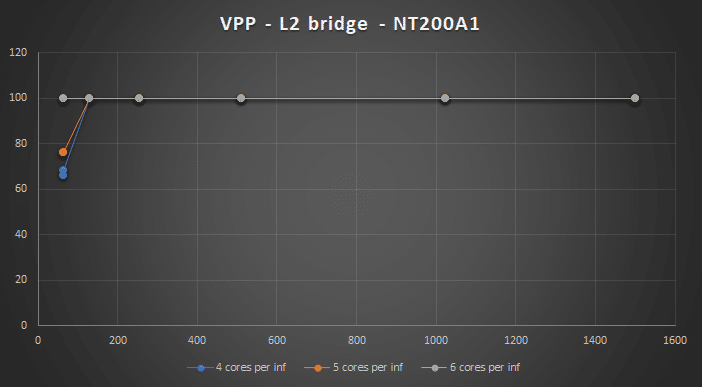
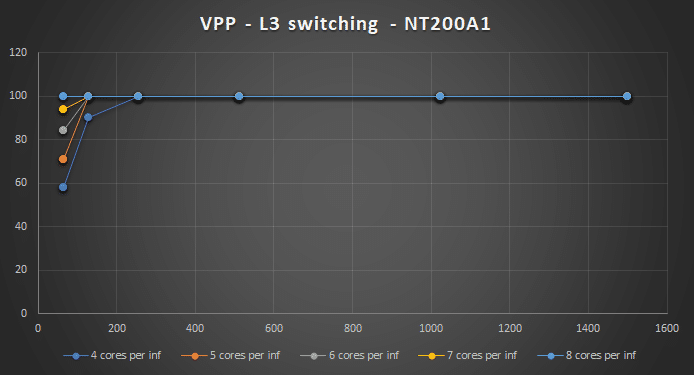
L2 xconnect and L2 bridging can be done using 6 cores per interface, which fit well into the 12 cores per NUMA system I have. When doing L3 switching I had to use a mixed NUMA setup and use 8 cores per interface to achieve 2x50Gbps @ 64B packets, but still durable.
Is 2x100GbE possible
The NT200A01 is a 2x100GbE NIC and so far, the tests have been on how many cores are needed to handle 100Gbps in total, but what if the traffic is asymmetric? In this case VPP must be able to handle 100Gbps from either of the interfaces. The setup I have created for this test run the two interfaces on the same 12 cores on NUMA1, so each core services a queue from port0 and a queue from port1.
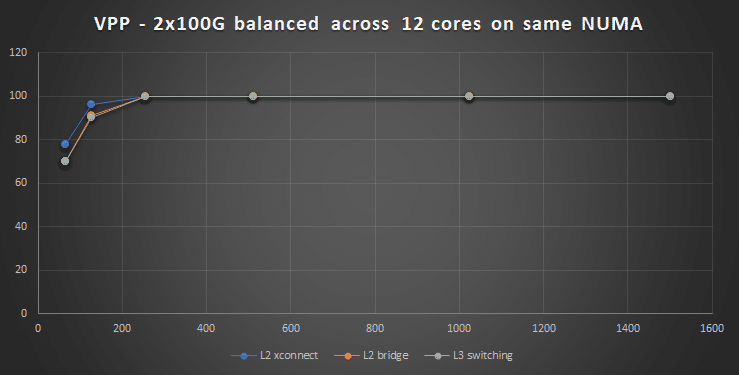
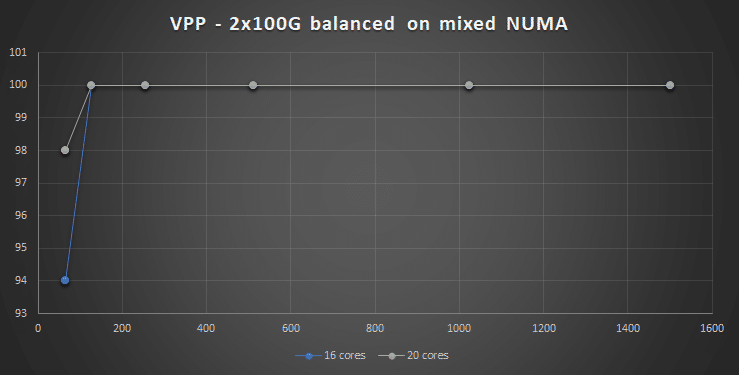
The funny thing is (not shown in the graph) when I send 100Gbps on one port only then 12 cores can easily handle the 100Gbs but when applying 100GbE to both, then performance is as shown in the graph above and then 12 cores are not enough. I tried the same setup in a mixed NUMA to see if adding cores from the remote NUMA would help, but it didn’t, at least not for 64B packets.
Conclusion
With the optimizations I made to the Napatech driver and Napatech DPDK PMD, VPP runs faster on Napatech. With the NT200A01 you can potentially do balanced 100Gbps (on a higher performing system than mine) switching/routine. The 100Gbps is limited by the x16 PCIe3, a true 2x100GbE system would require two 100GbE NICs one on each NUMA.. The Mellanox NIC has PCIe Gen4 support, but I don’t honestly think it will enable them doing 2x100Gbps, when they can’t even do 100Gbps.
Future work
The tests I have done with VPP on Napatech still requires some effort. I would especially like to have a method to select individual ports from the multi-port NICs sharing the same PCI bus-ID.
Related Posts


