As Communications Service Providers (CSPs) worldwide scale up the deployments of their 5G networks, they face strong pressure to optimize their Return on Investment (RoI), given the massive expenses they already incurred to acquire spectrum as well as the ongoing costs of infrastructure rollouts.
The Challenges of 100g Network Analysis
The data growth curve and need for 100G network analysis
With the current data growth and explosion, we are experiencing a growing demand for a transition into higher capacity networks in order to be able to meet with the growing network and data needs. As a solution, the telecom core networks and enterprise data centers recently introduced the 100G technology and 100G links, and with this, the transition from 10G to 100G became more of a reality. Also, the 10G link monitoring turned into 100G link monitoring.
You can read more about the 100G area in this blog:
https://www.napatech.com/smarter-data-delivery/
The challenges
Making the transition from 10G to 100G network analysis might sound easy but in fact, it introduces new challenges in terms of system performance and offload requirements.
The analysis of bidirectional flows on 100G network links requires capture of up to 2 x 100G line rate traffic, transfer of the captured traffic to the server memory and a full utilization of the multicore server system for processing the captured traffic.
Challenge 1: Full packet capture – zero packet loss
The analysis applications depend on complete capture of traffic under all conditions. This includes a bursts of 64 byte packets at 100G line rate. For this, a specialized network adapter, such as the Napatech NT100E3, is needed to guarantee full packet capture.
Challenge 2: PCIe bottleneck
Depending on the network adapter and server system used, the PCIe Gen3 will support up to 115G packet transfer rate when the PCIe overhead is taken into account. Depending on the system design approach the PCIe bottleneck is a limitation when monitoring 100G links.
Challenge 3: Server system utilization
In most use cases the network analysis involves a correlation of the bidirectional flows. An efficient application processing of flows requires that both directions of each flow are handled by the same CPU core. The challenge is to correlate up/down stream flows and transfer packets from 2 Ethernet ports to the same CPU core and at the same time utilize all the available CPU cores in the server system efficiently. The communication between the CPU sockets involves the Intel Quick Path Interconnect (QPI). Remember, a communication over the QPI introduces overhead and should be avoided.
So what are the options?
There are three different approaches for monitoring up/down link 100G traffic over optical taps. Each approach has pros and cons in relation to full packet capture and system performance.
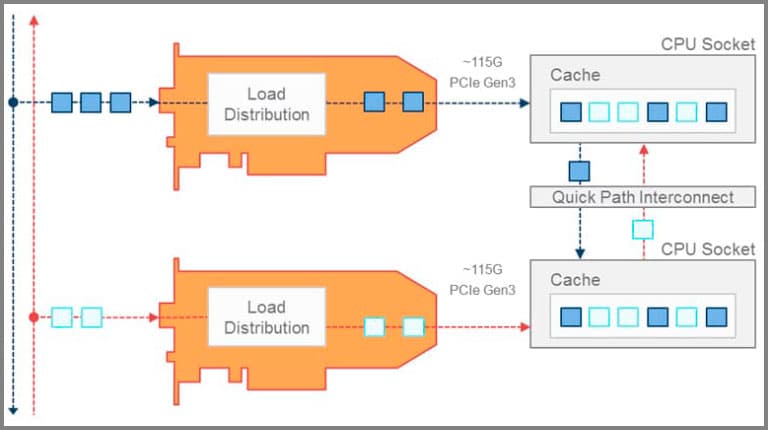
Approach 1: Single PCI slot
In this solution, the network adapter has 2 ports and interfaces to the host system over a single PCIe interface. The up/down stream flows captured on the 2 Ethernet ports are correlated and transferred to the CPU queues on the server system. Only the CPU cores on the CPU socket attached to the PCIe slot with the network adapter have direct access to the data. Utilizing other CPU cores in the system requires communication over QPI, which introduces overheads and reduced application performance.
An efficient load distribution over the CPU cores depend on well-designed distribution technics and data retrieved from packet headers outside or inside the tunnels or encapsulations.
The obvious limitation of the single PCI slot solution is the PCIe bandwidth bottleneck. The solution cannot handle sustained bandwidth above 115G. But on-board buffer memory can somehow compensate for the limitation and enable capture of bursts of line rate traffic.
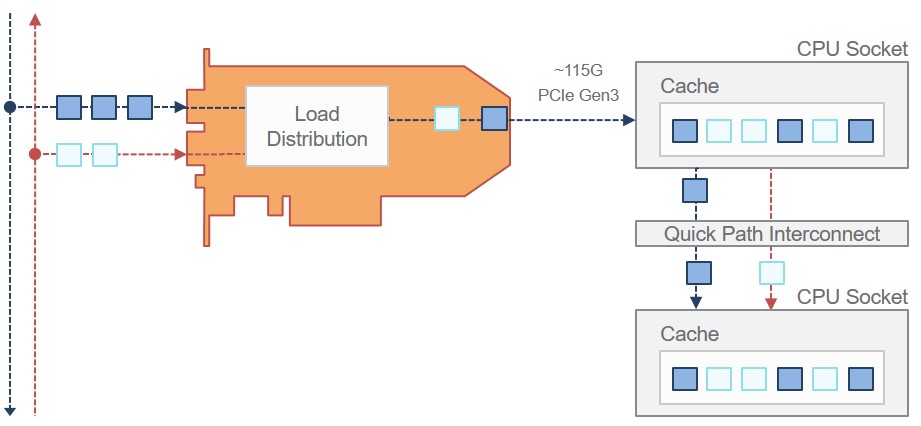
Approach 2: Dual PCI slot with independent flow transfer
Another solution is to utilize 2 PCI slots and capture up/down link traffic on 2 separate network adapters. This approach eliminates the PCIe bandwidth limitation completely and guarantees full line rate capture and delivery to the server memory, assuming sufficient server system performance.
Traffic from the upstream flow direction is delivered to the CPU cores on one CPU socket whereas the traffic from the downstream flow direction is delivered to CPU cores on another CPU socket. Correlation between the up and downstream flow directions have to be handled by the application. Since up and down stream traffic is delivered to different CPU sockets, the correlation process involves communication over QPI. For CPU bound applications the overhead can be critical.
![]()
Approach 3: Dual PCI slot with inter PCI slot flow transfer
In this approach hardware interconnect between the 2 PCIe network adapter is introduced. The purpose of interconnectivity is to direct the up and downstream flows to the correct CPU cores without the need for application communication over the QPI. Each network adapter is configured to distribute the up and downstream to the correct CPU sockets. This approach completely makes up for the QPI communication overhead.
A potential limitation of this solution is the oversubscription of one of the PCIe interfaces due to asymmetrical load distribution. Nevertheless, in general a highly loaded 100G link carry a large amount of flows, which means the load distribution will be evenly balanced over CPU cores.
For example the Napatech 2 x 100G Network Accelerator kit, NT200C01 supports this approach.
![]()

What is the conclusion?
The design decision should be based on optimizing the performance of the main bottleneck in the system. When analyzing 100G links the application is the bottleneck in most cases. Consequently, a design which optimizes the server resource utilization is preferable and Approach 3 is the best solution.
If the use case allows data reduction, such as dropping certain traffic categories based on filter criteria, then Approach 1 can be an alternative. Data reduction can compensate for the PCIe Gen3 bandwidth bottleneck and also reduce the need for balancing the load across the CPU sockets.
The future
In conclusion, it is very clear that PCIe Gen4 doubles the capacity compared to PCIe Gen3 and opens up for network adapter designs supporting line rate transfer of 2 x 100G traffic from network ports to server host memory. This solves the PCIe Gen3 bottleneck and enables implementation of full line rate capture 2 port 100G network adapters in a single PCI slot. This is great, but what about server system utilization? Flow distribution across all CPU cores still involves the QPI and related system overhead. The big question is: Will Intel improve QPI performance or will they introduce another concept for inter-CPU communication?
Related Posts


