As Communications Service Providers (CSPs) worldwide scale up the deployments of their 5G networks, they face strong pressure to optimize their Return on Investment (RoI), given the massive expenses they already incurred to acquire spectrum as well as the ongoing costs of infrastructure rollouts.

ACL HW acceleration in VPP shows great performance improvements
ACL HW acceleration improves performance. This blog can be considered a continuation of my previous blog , which was about Vector Packet Processing (VPP) (https://www.napatech.com/vpp-200g-nic/). In that article, I left out HW acceleration and so I will be focusing on that in this post.
What to accelerate?
In the first blog, I thought it would make sense to offload/accelerate the L2/L3 graph nodes, but after looking at the implementation of the L2 and L3 graph nodes, I decided to look elsewhere.
From the discussions I follow on Open vSwitch (OVS), it seems that security groups/access control lists (ACL) impose a huge performance penalty once they are activated.
I found this page https://wiki.fd.io/view/VPP/SecurityGroups, which shows that once security groups are activated in VPP, the forwarding performance is halved, and the performance degrades with the number of rules applied.
Looking at the implementation of ACL, I realized that it would be easy to implement HW acceleration, while keeping the SW implementation as a fallback.
Graph node interaction
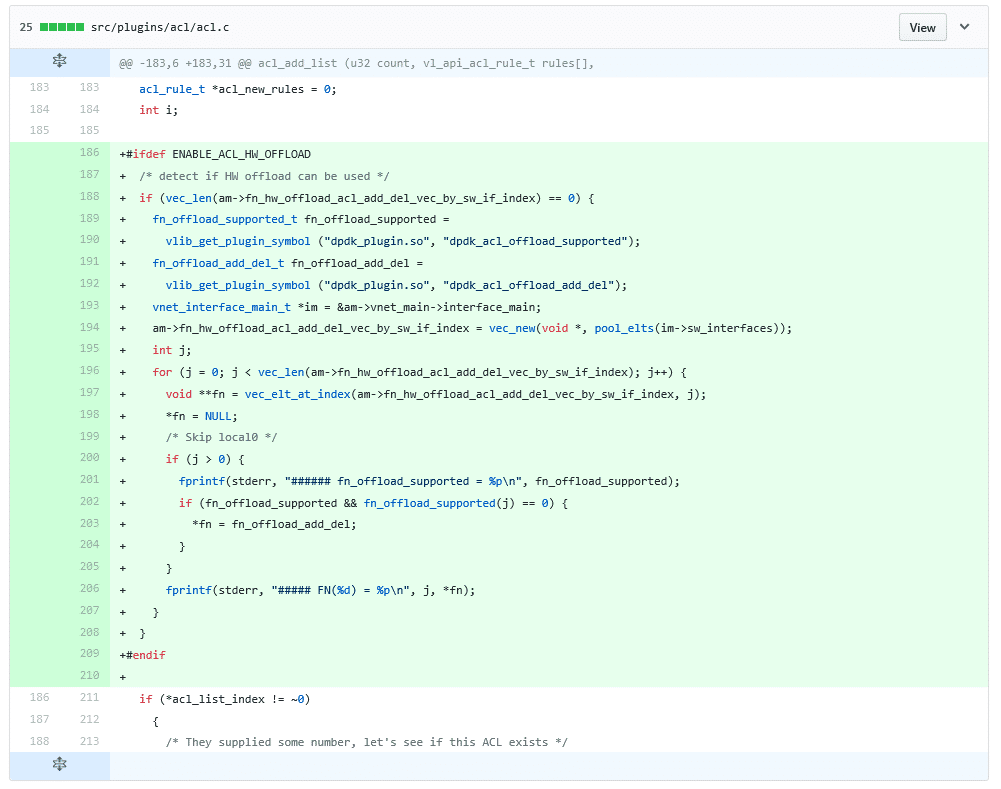
To have a clean design, it is best to have the ACL node independent of HW programming. That’s why HW programming should be done in the DPDK node. The DPDK node must expose an abstraction API that, if present, will be called from the ACL node.
A solution to this would be to use the binary API (message passing API), but to me it seems like a bit of an overkill. From the VPP mailing list I was made aware of the “vlib_get_plugin_symbol” function.
void* vlib_get_plugin_symbol(char *plugin_name, char* symbol_name)
With this, I’m able to probe within the ACL node if the DPDK node has support for the ACL acceleration functions and get the function pointers.
ACL HW acceleration implementation
The ACL HW acceleration is implemented by letting the HW tag packets with a value if they match a HW rule. The tag values are either DENY or PERMIT and I have not implemented PERMIT+REFLECT because connection tracking is not yet available in the NICs at my disposal. The ACL node will check the flags of the packets and if tagged, the action indicated by the tag will be performed without any further SW parsing.
This approach also means that while the HW is being programmed, the SW implementation will take control until the HW is ready to match the packets received.
ACL rules can be programmed to HW via the DPDK Generic Flow API (https://dpdk.org/doc/guides/prog_guide/rte_flow.html). The generic flow API might not be a perfect match for ACL rules because it doesn’t exactly work as an ACL, but as a flow matcher. However, for the example rules used in https://wiki.fd.io/view/VPP/SecurityGroups, it works to serve the purpose of showing the effect of HW offloading of ACL.
When the rules are programmed into HW, the action to apply when a match is found is to MARK the packets with the DENY or PERMIT value so that the DPDK input node can detect if a packet has been matched and convert the rte_flow mark value to a VLIB_BUFFER flag.
The DPDK node exposes the following API for ACL offload:
- int dpdk_acl_offload_supported(u32 sw_if_index);
Called to determine if ACL HW offload can be done on the interface indicated by if_index - void dpdk_acl_offload_add_del(void **handle, acl_rule_t *rule, u32 sw_if_index, u8 is_input, u8 is_add);
Called to add/delete an ACL rule. When adding an ACL rule, a handle to the created rule is returned. The ACL handle must be provided when deleting the rule
The ACL node will, when activated, probe the interfaces and check if HW acceleration can be used or not. This probing is implemented within the acl_add_list() function in acl.c as a singleton. ACL rules are pushed and removed from HW within the hash_acl_apply() and hash_acl_unapply() functions in hash_lookup.c.
The working implementation can be found in the Napatech github page: https://github.com/napatech/vpp/tree/acl_rte_flow
Test results
The tests conducted are based on the tests found in https://wiki.fd.io/view/VPP/SecurityGroups
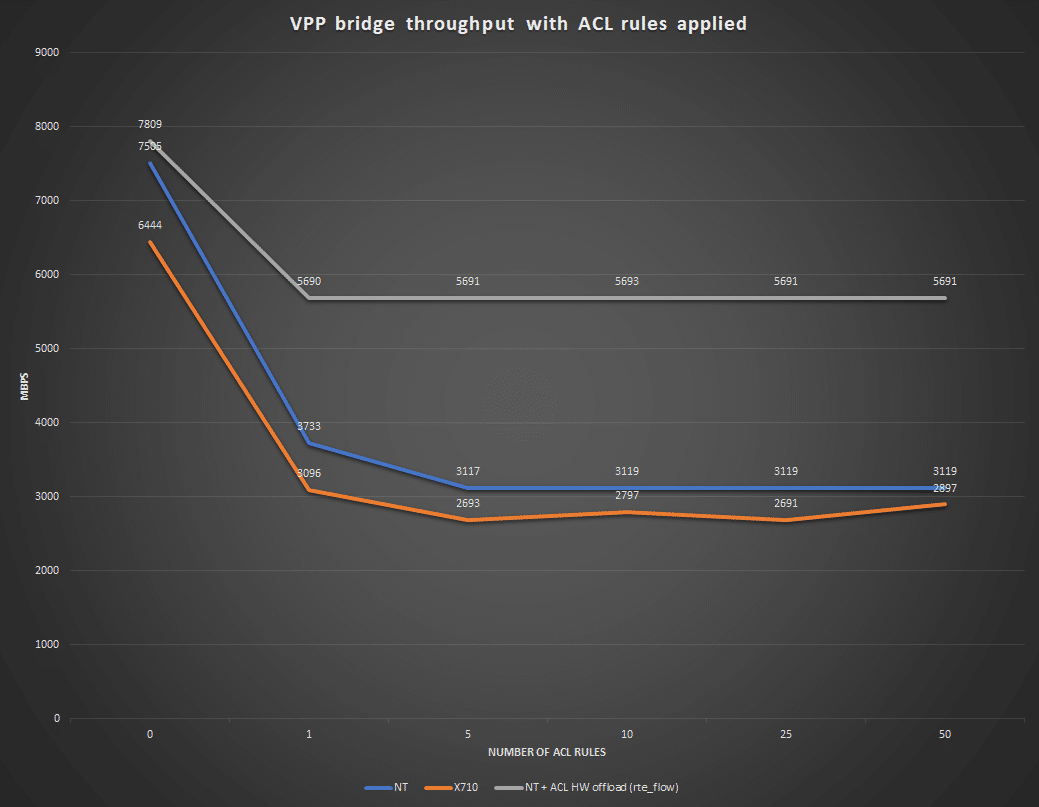
The only exception to the procedure in the link above is that the ACL rules are only applied in the ingress direction.
The result of the tests show that almost twice the performance is achieved by implementing HW acceleration.
The tests were run on a Dell R730, E5-2690 v3 @ 2.6GHz with a NT40E3-4 SmartNIC (https://www.napatech.com/support/resources/data-sheets/nt40e3-smartnic-capture/). The traffic, 20.000 UDP flows with a packet size of 64B, was generated using the TRex traffic generator (https://trex-tgn.cisco.com/) on another NT40E3-4 in another server.
Conclusion
The test results show that there is a huge performance improvement when accelerating ACL and that it might be a very viable case to build a true ACL rule handler in HW, one that can run with a prioritized list of independent rules instead of a flow-based approach. How many rules should be offloaded in HW is difficult to say, but around a couple of thousands systemwide might be enough when looking at what HW switches support today:
Related Posts


