As Communications Service Providers (CSPs) worldwide scale up the deployments of their 5G networks, they face strong pressure to optimize their Return on Investment (RoI), given the massive expenses they already incurred to acquire spectrum as well as the ongoing costs of infrastructure rollouts.
Burst! Does it matter if packet bursts are contiguous or scattered?
NTAPI vs DPDK – Contiguous packet burst vs scatter packet burst
The packet burst method can be crucial to achieve high performance. Napatech recently added support for DPDK on its FPGA SmartNICs (https://github.com/napatech/dpdk), but how is performance compared to the native NTAPI? This blog will look at the two methods for bursting packets, contiguous packet burst vs scattered packet burst – NTAPI vs DPDK.
Contiguous packet burst
Napatech has always supported contiguous packet burst or segments as they are called within Napatech. A contiguous packet burst is a contiguous memory buffer containing multiple packets arranged back-to-back, like the layout of a PCAP file. Each packet has a descriptor prepended which describe the packet and contain as a minimum a timestamp and a packet length, but can also contain much more advanced and dynamic metadata.
The huge benefit of using this contiguous packet burst method is:
- Line-rate PCIe utilization enabling true zero packet loss @100Gbps on a x16 PCIe bus
- High memory data locality when traversing packet because it allows the HW prefetchers to fetch into L1 cache whereas prefetch hints only provide L2 cache prefetching.
- The cache lines that are prefetched are most likely to be used because they contain the next packet especially
4x10G line-rate using DPDK
The NIC used for the comparison between NTAPI contiguous burst and DPDK scattered burst is a Napatech 4 port 10G SmartNIC (NT40E3-4). DPDK support on this adapter is fairly new so a DPDK baseline is needed and for that the DPDK testpmd application is used.
Testpmd was run in rxonly receiving 1.000.000.000 packets @10Gbps on all 4 ports simultaneously each test run at a different packet size.
# testpmd -c 0x5555 --vdev eth_ntacc0,port=0 --vdev eth_ntacc1,port=1 --vdev eth_ntacc2,port=2 --vdev eth_ntacc3,port=3 -- --forward-mode=rxonly --portmask=15 --nb-cores=4
Checking link statuses...
Port 0 Link Up - speed 10000 Mbps - full-duplex
Port 1 Link Up - speed 10000 Mbps - full-duplex
Port 2 Link Up - speed 10000 Mbps - full-duplex
Port 3 Link Up - speed 10000 Mbps - full-duplex
Done
No commandline core given, start packet forwarding
rxonly packet forwarding - ports=4 - cores=4 - streams=4 - NUMA support disabled, MP over anonymous pages disabled
Logical Core 2 (socket 0) forwards packets on 1 streams:
RX P=0/Q=0 (socket 0) -> TX P=1/Q=0 (socket 0) peer=02:00:00:00:00:01
Logical Core 4 (socket 0) forwards packets on 1 streams:
RX P=1/Q=0 (socket 0) -> TX P=0/Q=0 (socket 0) peer=02:00:00:00:00:00
Logical Core 6 (socket 0) forwards packets on 1 streams:
RX P=2/Q=0 (socket 0) -> TX P=3/Q=0 (socket 0) peer=02:00:00:00:00:03
Logical Core 8 (socket 0) forwards packets on 1 streams:
RX P=3/Q=0 (socket 0) -> TX P=2/Q=0 (socket 0) peer=02:00:00:00:00:02
rxonly packet forwarding - CRC stripping disabled - packets/burst=32
nb forwarding cores=4 - nb forwarding ports=4
RX queues=1 - RX desc=128 - RX free threshold=0
RX threshold registers: pthresh=0 hthresh=0 wthresh=0
TX queues=1 - TX desc=512 - TX free threshold=0
TX threshold registers: pthresh=0 hthresh=0 wthresh=0
TX RS bit threshold=0 - TXQ flags=0x0
Press enter to exit
Telling cores to stop...
Waiting for lcores to finish...
---------------------- Forward statistics for port 0 ----------------------
RX-packets: 1000000000 RX-dropped: 0 RX-total: 1000000000
TX-packets: 0 TX-dropped: 0 TX-total: 0
----------------------------------------------------------------------------
---------------------- Forward statistics for port 1 ----------------------
RX-packets: 1000000000 RX-dropped: 0 RX-total: 1000000000
TX-packets: 0 TX-dropped: 0 TX-total: 0
----------------------------------------------------------------------------
---------------------- Forward statistics for port 2 ----------------------
RX-packets: 1000000000 RX-dropped: 0 RX-total: 1000000000
TX-packets: 0 TX-dropped: 0 TX-total: 0
----------------------------------------------------------------------------
---------------------- Forward statistics for port 3 ----------------------
RX-packets: 1000000000 RX-dropped: 0 RX-total: 1000000000
TX-packets: 0 TX-dropped: 0 TX-total: 0
----------------------------------------------------------------------------
+++++++++++++++ Accumulated forward statistics for all ports+++++++++++++++
RX-packets: 4000000000 RX-dropped: 0 RX-total: 4000000000
TX-packets: 0 TX-dropped: 0 TX-total: 0
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Done.
NT40E3-4 using DPDK could achieve zero packet loss at all packet sizes, the same as if NTAPI was used.
| 64 byte | 128B | 256B | 512B | 1024B | 1518B | |
| NT40E3-4 | 40G | 40G | 40G | 40G | 40G | 40G |
Test application
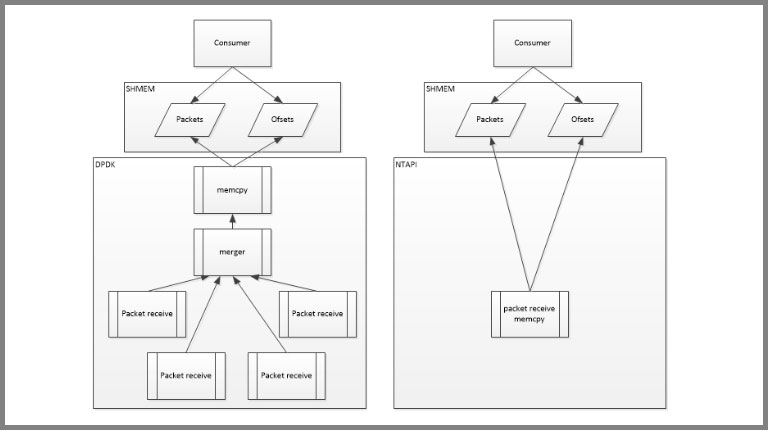
The test application requires packets from all ports into a single queue. Packets must be stored in its own application shared memory (SHMEM), in a PCAP like manner, back-to-back in contiguous memory. A worklist containing offset and length of the individual packets is needed to go along with the packets.
The DPDK implementation and the NTAPI implementation of the underlying driver differs.
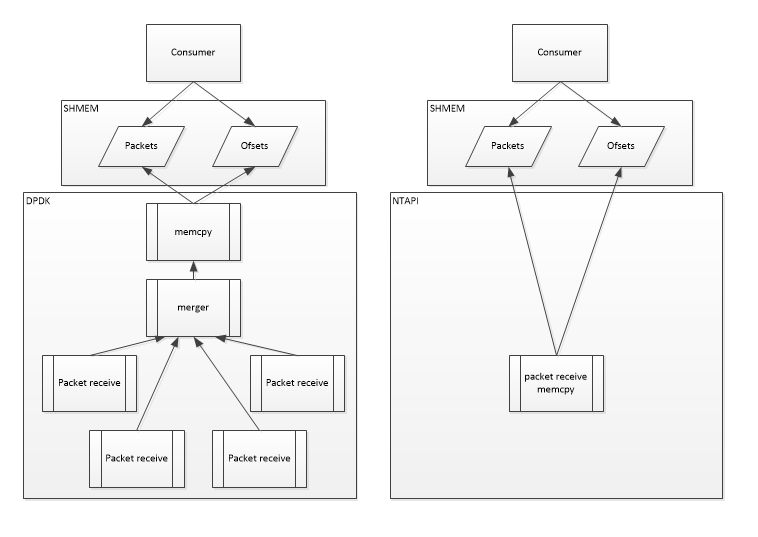
DPDK design
Several design solutions were tried and this design is the one that gave the highest throughput, the memcpy turned out to be the bottleneck and must run isolated in its own core.
The pipeline steps perform the following operations:
- Packet receive
- Runs in its own lcore to ensure 10Gbps zero-drop
- Packets are received in burst of 32
- The burst is timestamped using rte_rdtsc()
- The burst is placed in a queue enabling the merger lcore to receive the burst
- Merger
- Receive a burst from all packet receive queues
- Timestamp compare burst and use the oldest
- Place burst in a queue enabling the memcpy lcore to receive the burst
- Memcpy
- Read a burst from the queue between the merger and the memcpy
- rte_memcpy() packets into the SHMEM and create a packet offset list. Release packets and list to the consumer
- Free the burst back to the memory pool
NTAPI design
NTAPI can enable the NT HW to timestamp merge the traffic into one stream. In this design the memcpy and the packet receiver could actually run on the same core without any performance issues.
- Packet receive/memcpy
- Receive a contiguous burst of packets
- memcpy() (the glibc version) packets into the SHMEM and create a packet offset list. Release packets and list to the consumer
- Free the burst
Measurements
The performance in the table below clearly show a significant performance drop using DPDK when packet sizes are < 256B, whereas NTAPI runs full line-rate in all cases.
The reason NTAPI throughput is better is because the HW prefetcher help the memcpy quite a lot, so where DPDK has lots of L2 cache misses, there are almost no L2 misses in NTAPI.
Besides the throughput, the number of cores needed is much less (2 in NTAPI vs 7 in DPDK), but that is mainly due to the merge part being offloaded to HW.
| 64 byte | 128B | 256B | 512B | 1024B | 1518B | |
| DPDK | 24G | 37G | 40G | 40G | 40G | 40G |
| NTAPI | 40G | 40G | 40G | 40G | 40G | 40G |
Note: Another difference between NTAPI and DPDK is that DPDK call rte_memcpy() for each packet whereas NTAPI call memcpy() for every ~1MB, but even if the 1MB is traversed and memcpy is called per packet the throughput stays the same, which just substantiates that it really is the L1 prefetching that boost performance.
What about NUMA/QPI
Another interesting test was to place the consumer and the SHMEM on another NUMA node than the receive part, forcing packets to be copied across QPI.
| 64 byte | 128B | 256B | 512B | 1024B | 1518B | |
| DPDK | 13G | 18G | 33G | 40G | 40G | 40G |
| NTAPI | 38G | 40G | 40G | 40G | 40G | 40G |
The outcome of this test shows that while performance drops using both DPDK and NTAPI, the contiguous burst makes a huge difference.
Contiguous burst utilized in NFV
Napatech is developing (work in progress) offload acceleration for OVS (Open vSwitch), which can be followed at https://github.com/napatech/ovs . In addition to the actual offload itself, the use of contiguous bursts further accelerates the system performance. Napatech has added support for contiguous bursts to DPDK as part of our OVS-DPDK development.
Napatech have made a Snort 3.0 DAQ DPDK multiqueue module (https://github.com/napatech/daq_dpdk_multiqueue), to enable RSS when running Snort as a VNF. Snort works perfectly with contiguous bursts because it gets a reference to the packet and will return a verdict to either drop the packet or pass it, and it never needs to keep the packet and release it out-of-order.
With this DAQ module and our current OVS implementation we have found that not only does contiguous burst improve Snort performance from 1.15Gbps/core to 1.42Gbps/core it also makes the Snort setup scale across NUMA/QPI.
We made the current setup and tested with Snort running one socket and on both sockets.
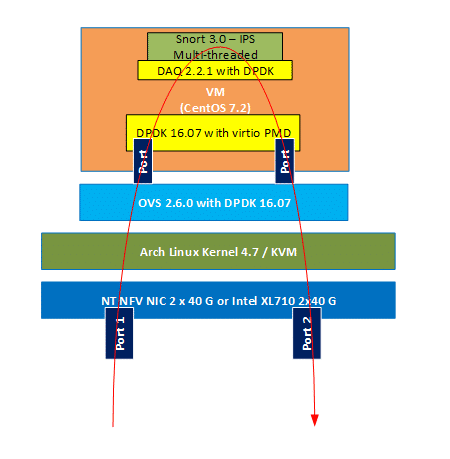
The results of the tests run, are shown in the table below.
| OVS type | OVS cores used | Snort cores used | NUMA0 | Snort cores used | NUMA1 | Performance | Performance/core |
| Vanilla | 4 | 8 | 9.2 Gbps | 1.15 Gbps/core | |
| NT | 2 | 12 | 17 Gbps | 1.42 Gbps/core | |
| Vanilla | 8 | 6 | 14 | 13 Gbps | 0.65 Gbps/core |
| NT | 4 | 10 | 14 | 34 Gbps | 1.42 Gbps/core |
The tests details:
- a HP DL380 Gen-9 server without Hyperthreading, Xeon 2697 E5 v3 – 14 cores pr socket. Two sockets available, so a total of 28 cores
- QEMU version 2.6.0
- Xena traffic generator and receiver
- Using 68b -> 256b random packets (Eth+IPv4+UDP)
- Measuring what is received back to Xena
The results show that using only one NUMA node the vanilla OVS system runs best (Gbps/core) with 4 OVS cores and 8 Snort cores. The reason we didn’t use 10 Snort cores or another mix was that it only gave lower Gpbs/core ratio. The NT OVS on one NUMA node needed half the OVS cores and could scale to use the rest of the cores for Snort and thereby get more throughput and also a better Gbps/core ratio.
When distributing to Snort on both NUMA nodes, Vanilla OVS didn’t perform and the Snort Gbps/core ratio becomes half of what it was when not crossing the QPI. NT OVS on the other hand scaled linear.
Conclusion
Even though the test application might be synthetic, the OVS with Snort 3.0 clearly show that the contiguous burst can increase performance and scalability.
The synthetic application lack one important property when using DPDK, proper port merge. The port merging done using DPDK doesn’t really guarantee correct packet ordering, because the packets are merged on a per burst basis. Using NTAPI the port merging guaranteed by the NIC on a per packet basis.
Related Posts


